- Структурируйте ваше приложение таким образом чтобы максимально использовать паралеллизм. (я бы добавил : используйте подход «shared nothing» по максимуму)
– Постарайтесь уменьшить передачу данных с/на видеокарту. От себя : для GeForce 2xx и всех программируемых Radeon (поскольку возможно асинхронная передача данных – тоесть во время вычислений) можно маскировать задержки передачи данных на видеокарту если у вас один кернел вызывается многократно или несколько подряд.
– Для жирафов советуют coalesce global memory accesses, и судя по результатам теста это одинаково полезно для всех видеокарт (рандом рид у всех одинаково медленный). Суть же в том что к памяти нужно обращятся последовательно. От себя – есть два способа: первый состоит в том что нужно так написать код что бы адресс ячейки памяти к которой должен обратится тред за параметрами должен быть функцией от номера треда, второй – из памяти читает только один тред и сразу записывает всё что прочитал в локальный кеш, что казалось бы тоже разумно если бы не падение производительности в результате того что остальные треды в это время простаивают, что в общем называется branch divergence и само по себе очень не хорошо.
– Используйте локальную память, shared memory в CUDA и LDS в чипах AMD. Признаю совет банальный.
– Локальная память в чипах nVidia поделена на банки, и желательно устранить одновременное обращение на запись к одному банку от более чем 4-ёх тредов. Актуальноть для карт АМД следует выяснить.
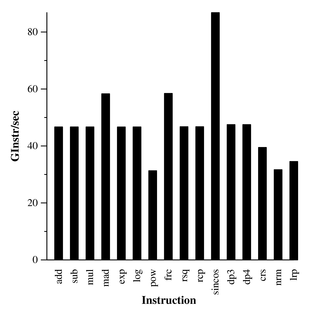
– Не все инструкции одинаково полезны, часть инструкций реализовано программно с помощью нескольких более простых инструкции, в доке описано какими хаками выполнять те же действия, без дорогих инструкций, хаки работают не всегда. В описанном ранее тесте можно посмотреть какие именно инструкции на каких картах тормозят.
– Постарайтесь ораганизовывать ветвления на уровне SIMD engine, тоесть что бы в каждом варпе все треды делали одну и ту же работу, для аргументами ветвлений должны быть номера варпов, но не тредов. Подобное получится не всегда. Придется выворачивать алгоритм. Напишу как-то как вывернул один алгоритм (распространения сигнала между слоями нейросети), для того что бы не использовать запись по произвольному адресу. В упоминавшемся уже тесте ветвления на жирафе были бесплатными, возможно авторы просто не смогли достичь необходимого эффекта, а возможно дело в разном количестве элементов в SIMD блоке.
Разные ссылки :
http://www.gpgpu.org/s2007/slides/03-data-parallel-algorithms-and-data-structures.pdf
http://www.cs.unc.edu/~naga/parcomp07.pdf - Эффективное использование кеша
http://www.cs.unc.edu/~naga/sc06.pdf - Модели памяти