четверг, 15 октября 2009 г.
Набодяжил
суббота, 27 июня 2009 г.
Используем вычислительную мощь ATI StreamComputing CAL с простотой C# (из .NET)
В посте описывается мой вариант процесса программирования видео карт и моя библиотека для использования ATI StreamComputing из .NET языков (в примере C#). По сути это оболочка над ранее написанной библиотекой useGPU. Логика работы с видео картой и процесса разработки приложения осталась прежней. Объясню на примере.
Шаг 1. Написание шейдера.
Вот шейдер написанный на HLSL. Каждый поток читает все элементы одномерной текстуры и суммирует их. Соглашусь шейдер не практичен - результаты всех потоков идентичны. Для того что бы разные потоки читали свои массивы из разных участков двухмерной текстуры нужно подправлять код в ассемблере.
//описание семплера нужно как формальность, далее мы о нём совсем забудем.
SamplerState S
{
};
//текстура из которой будем читать данные
Texture1D Input;
/*описываем структуры входящих значений для шейдера (не константы и не данные текстуры )*/
struct VS_OUTPUT
{
float2 pos : POSITION;
/*семантика нужна компилятору, он думает что у нашего шейдера есть некая графическая специфика. Семантику POSITION*, где * - номер элемента текстуры можно прописать к любому типу поля - даже вашему собственному*/
};
struct PS_OUTPUT
{
int bla: SV_Target1;
/*ситуация аналогична предудущей*/
};
float get(Texture1D t, float coord)
{
return t.Sample(S,coord);
//для того что бы забыть о семплерах совсем
}
PS_OUTPUT main (VS_OUTPUT In)
{
PS_OUTPUT Output;
Output.bla = 0;//инициализация - иначе компилятор ругается
for(int i = 0; i < color="#cc0000"> return Output;
}
IMHO: HLSL может оказатся удобнее чем brook+, в нём неофициально есть классы и обьекты, по крайней мере документации я об этом не видел. Классы не поддерживают конструкторов/деструкторов, статических переменных/функций и виртуальных функций, но это не очень страшно по моему. Сама возможность инкапсуляции уже гуд. В 11-ом DirectX это всё появится официально плюс много других плюшек. Но думаю резон использовать ATI StreamComputing всё равно останетя - меньше задержки при обращении к устройству.
Пример валидного кода с классом :
class my
{
int4 a;
//это не конструкто
void my()
{
a = 2;
}
void bla();
};
void my::bla()
{
this.a += 1;
}
struct PS_OUTPUT
{
my bla: SV_Target1;
//подобное обьявление позволяет забыть о семантике и менять только свой класс
};
Недостатоков всего два :нужно править шейдер на асме (для доступа к номеру потока или local memory), и нужно переключатся между средами - что совсем не сложно. С другой стороны - AMD-шный компилятор HLSL содержит различны расширения - так что можно обращатся к ассемблеру редко. После выхода DirectX 11 первый недостаток отпадёт - можно будет писать на computing shaders.
Шаг 2. С помощью AMD GPUShaderAnalyzer 1.47 (или ниже))) - из более поздних такую возможность убрали ) получаем для нашего шейдера Intermediate Language.
Шаг 3. Написание хост кода использующего шейдер.
Код на C#, использующий вышеуказанный шейдер скомпилированный в CAL IL (унифицированный ассемблер видеокарт ATI, который если честно очень слабо отличается от D3D assembly).
string s = @"il_ps_2_0
dcl_cb cb0[1]
dcl_output_generic o0.x___
dcl_resource_id(0)_type(1d,unnorm)_fmtx(float)_fmty(float)_fmtz(float)_fmtw(float)
; l0 = (0.000000f 0.000000f 0.000000f 0.000000f)
; l0 = (0.000000f 0.000000f 0.000000f 0.000000f)
dcl_literal l0, 0x00000000, 0x00000000, 0x00000000, 0x00000000
mov r0.xyz_, l0
whileloop
ige r0.___w, r0.z, cb0[0].x
break_logicalnz r0.w
itof r0.___w, r0.z
sample_resource(0)_sampler(0) r1, r0.w
iadd r0.x___, r0.x, r1.x
; l2 = (0.000000f 0.000000f 0.000000f 0.000000f)
dcl_literal l2, 0x00000001, 0x00000001, 0x00000001, 0x00000001
iadd r0.__z_, r0.z, l2
endloop
mov o0.x___, r0.x
ret_dyn
end";
/*Инициализируем связь с CAL runtime, узнаём что у нас за устройство в системе и какими характеристиками оно обладает */
dotGPU.GPU g = new dotGPU.GPU();
/*компилируем нашу программу*/
g.CreateImage(s, 0);
//создаём текстурку - знаю было бы быстрее с использованием массивов.
var data = new List<int>();
data.Add(123);
data.Add(456);
//Копируем текстуру на видеокарту и получаем номер соответствующего ей ресурса
int n1 = (int)g.Allocate(0, false, data, 2, 1, 20);
var data1 = new List<int>();
data1.Add(2);
//аналогичный процесс для константы
int n2 = (int)g.Allocate(0, false, data1, 1, 1, 20);
int o = (int)g.Allocate(0, true, null, 64, 1, 20);
/*Запускаем на выполнение шейдер 0 на устройстве 0, размер домена выполнения(количество тредов) равен размеру аргумента 2, связываем хендлеры ресурсов с регистрами шейдера и получаем в результате хендлер задачи*/
int e = (int)g.Execute(0, 0, 2,
new List<string>() { "i0", "cb0", "o0" },
new List<int>() { n1,n2,o});
//ждём пока не закончится выполнение шейдера
while (!g.Wait(0, e));
//забираем результат
data1 = g.GetResult(o);
//завершаем работу с видеокартой - это нужно делать явно!
g.Close();
Шаг 4. Release)
Шаг 5. Debug))))))
среда, 14 января 2009 г.
Правила gpgpu
- Структурируйте ваше приложение таким образом чтобы максимально использовать паралеллизм. (я бы добавил : используйте подход «shared nothing» по максимуму)
– Постарайтесь уменьшить передачу данных с/на видеокарту. От себя : для GeForce 2xx и всех программируемых Radeon (поскольку возможно асинхронная передача данных – тоесть во время вычислений) можно маскировать задержки передачи данных на видеокарту если у вас один кернел вызывается многократно или несколько подряд.
– Для жирафов советуют coalesce global memory accesses, и судя по результатам теста это одинаково полезно для всех видеокарт (рандом рид у всех одинаково медленный). Суть же в том что к памяти нужно обращятся последовательно. От себя – есть два способа: первый состоит в том что нужно так написать код что бы адресс ячейки памяти к которой должен обратится тред за параметрами должен быть функцией от номера треда, второй – из памяти читает только один тред и сразу записывает всё что прочитал в локальный кеш, что казалось бы тоже разумно если бы не падение производительности в результате того что остальные треды в это время простаивают, что в общем называется branch divergence и само по себе очень не хорошо.
– Используйте локальную память, shared memory в CUDA и LDS в чипах AMD. Признаю совет банальный.
– Локальная память в чипах nVidia поделена на банки, и желательно устранить одновременное обращение на запись к одному банку от более чем 4-ёх тредов. Актуальноть для карт АМД следует выяснить.
– Не все инструкции одинаково полезны, часть инструкций реализовано программно с помощью нескольких более простых инструкции, в доке описано какими хаками выполнять те же действия, без дорогих инструкций, хаки работают не всегда. В описанном ранее тесте можно посмотреть какие именно инструкции на каких картах тормозят.
– Постарайтесь ораганизовывать ветвления на уровне SIMD engine, тоесть что бы в каждом варпе все треды делали одну и ту же работу, для аргументами ветвлений должны быть номера варпов, но не тредов. Подобное получится не всегда. Придется выворачивать алгоритм. Напишу как-то как вывернул один алгоритм (распространения сигнала между слоями нейросети), для того что бы не использовать запись по произвольному адресу. В упоминавшемся уже тесте ветвления на жирафе были бесплатными, возможно авторы просто не смогли достичь необходимого эффекта, а возможно дело в разном количестве элементов в SIMD блоке.
Разные ссылки :
http://www.gpgpu.org/s2007/slides/03-data-parallel-algorithms-and-data-structures.pdf
http://www.cs.unc.edu/~naga/parcomp07.pdf - Эффективное использование кеша
http://www.cs.unc.edu/~naga/sc06.pdf - Модели памяти
вторник, 13 января 2009 г.
Обработка баз данных там же)))
Моё знакомство с gpgpu началось с вот этой статьи. Выделили несколько ресурсоёмких, паралельных подзадач при обработке ДБ и сгрузили на видаху. Прирост быстродействия от использования жирафа 5900 вместо ксеона на 2.8 в раёне 5-20 раз, правда у них это всё было сделано только для реляционных сценариев. Мне больше интересны СУООБД или ещё лучше MAP/REDUCE.
gpgpu на службе армии
Operations (TEMO); Advanced Concepts and
Requirements (ACR); and Research, Development and Acquisition (RDA). А вот дока в которой описывается как в таких приложения использовать видеокарты. В ней описывается одна из подзадач свойственная таким приложениям - ответ на вопрос какие бойцы видят каких вражеских бойцов (LINE OF SIGHT по ихнему). Помоему подобное должно быть реализовано в современных играх, шутерах. В статье описывается предложеный автором алгоритм частично сгружающий эту задачу на видаху. К сожалению статья очень древняя и там описывается испольозание 4-ого жирафа, в результате данный подход к совеременным карточкам применим слабо, а если и применим - то уж явно лучше написать самому. Хотя задачка интересная. В терминаторе точно стоит CrossFireX)))) Что забавно одна из подобных систем так и называется CROSSFIRE: an IDE for operational training. Вот ещё один кладезь знаний, на этот раз на тему моделирования всех и вся.
Алгоритмы и структуры данных в gpgpu
Нашёл интересную статью о программировании видах. Ничего координально нового просто всё очень красиво, академично изложено. Новичкам в gpgpu советую. Наиболее важное : на архитектуру видеокарт наиболее природно ложатся функциональные примитивы Map & Reduce, а так же Sort & Search (которые описываются в другой доке которую я пока не нашёл). Нашёл целый кладезь подобных публикаций просто найдя личную страница автора одной из интересных док на эту тему. Так же всем кто интересуется этой темой советую перечитать все публикации SIGGRAPH 200x какие найдёте, более старые мало смысла просто. Вот за 2008 и за 2007, последний даже интересней как для меня.
Исчё один тест

Результат кракера-ломакера MD5 BursWF на 64 битной системе windows server 2008 enterprise, Pentium DC 2160, RadeonHD 4670 ( всё на референсных частотах).
понедельник, 12 января 2009 г.
Моя маленькая радость
Решая свою текущую задачу (созадние нейроконструктора работающего на видахе) сделали с комрадом библиотеку для программирования видах AMD - уровень абстракции над уровнем абстракции над вычислениями ( Computation Abstraction Layer == CAL) кто видел примеры из AMD StreamComputing SDK (CAL) тот поймёт зачем это было сделано ( что бы писать меньше хост-кода для запуска каждой задачи ;-)).

Могу вас уверить обьём кода уменьшился в 4-5 раз. Вот пример простейшего приложения
#include "useGPU.h"
using namespace std;
std::string programIL =
"il_ps_2_0\n"
"dcl_input_interp(linear) v0.xy\n"
"dcl_output_generic o0\n"
"dcl_resource_id(0)_type(2d,unnorm)_fmtx(float)_fmty(float)_fmtz(float)_fmtw(float)\n"
"sample_resource(0)_sampler(0) r0, v0.xy\n"
"dcl_literal l0, 0x3F000000, 0x3F000000, 0x3F000000, 0x3F000000\n"
"sub r2.x, r0.x, v0.x\n"
"mov o0.x, r2.x\n"
"ret_dyn\n"
"end\n";
void main()
{
useGPU g;
float idata[256][256];
for (int i = 0; i < j =" 0;" odata =" NULL;" string=""> > params;
params.push_back( make_pair(0,"i0") );
params.push_back( make_pair(1,"o0") );
CALevent e = g.Execute(0,0,1,params);
while ( g.Wait(0,e) == CAL_RESULT_PENDING);
void* ret = g.GetResult(1);
odata = reinterpret_cast
for(int i = 0; i <>
{
for(int j = 0; j <>
Нестандартный бенчмаркинг видеокарт
Перечитывая презентации SIGGRAPH 2007 GPGPU COURSE, выложеные понятное дело на gpgpu.org наткнулся на интересную статью , к которой говорится что производительность видеокарт в gpgpu приложениях отличается от производительности в играх, у меня и раньше были подобные догадки, например GeForce 9600GT быстрее RadeonHD 3870 в большинстве игр, особенно в тяжёлых режимах при том что максимальная теоретическая производительность у неё около 100 Gflops (без matmul магии ), что почти в 2.5 раза меньше чем у карты ATI из которой на практике выжимали около 300 (с магией ))) конешно, данные из ReadMe.txt обычного brook - не brook+). С другой стороны 8800GT показывает себя в данном тесте гораздо лучше Radeon 2900XT. Что самое обидное - так это то что на жирафах ветвления бесплатные. Скачал вышеуказанный и для себя, интересно сравнить свой RadeonHD 4670 с Radeon 2900XT, больше всего волнует такой вопрос : что важнее ширина шины памяти или количество текстурных блоков (и соответственно объём текстурного кэша). Скачал тест и убедился в том что моя карта проигрывает Radeon 2900XT в тесте Basic Throughput в 4 раза при различных настройках, собственно в 4 раза у них и отличается ширина шины памяти, текстурных блоков у моей карты пожалуй побольше будет в 2 раза минимум (по сравнению с RadeonHD 3870). В тесте 4-Component Floating Point Input Bandwidth всё не так плачевно 68 GB/s против 150 GB/s. А вот результат теста Instruction Issue меня порадовал вверху диаграмма для монстра былых времён Radeon 2900XT, внизу скриншот с результатами моего питомца ;-))))
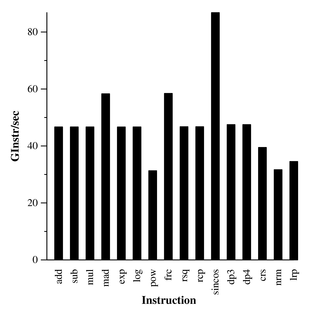

Как вывод можно отметить что результаты бенчмарков вроде 3DMark судя по всему меряют количество выполнения какого-то (каких-то) шейдеров на разных системах, в рамках различных игровых сценариев и поэтому результаты разных карт в них кореллируют с результатам вышеуказанного теста с положительным коэфициентом близким к единице .